
Pandas GroupBy and Count work in combination and are valuable in various data analysis scenarios. The groupby function is used to group a DataFrame by one or more columns, and the count function is used to count the occurrences of each group. When combined, they can provide a convenient way to perform group-wise counting operations on data. However, there are several reasons why you might want to use groupby and count. Before diving into those use cases, let’s first explore each of these in detail.
- Understand Pandas GroupBy() and Count()
- Pandas GroupBy()
- Pandas Count()
- Data Exploration Using Pandas GroupBy and Count
- For Generating Aggregated Summary
- How to Use for Data Cleaning
- Using for Reporting and Visualization
- Using GroupBy and Count with Condition
- Using Pandas GroupBy and Count for Data Preprocessing
- Ensuring Quality of Data
- Keep Code Clean and Efficient
Understand Pandas GroupBy() and Count()
In Pandas, the groupby method is a versatile tool for grouping rows of a DataFrame based on some criteria. It allows you to split a DataFrame into groups based on one or more columns and then apply a function to each group independently. Let’s learn how to use it in our Python code.
Pandas GroupBy()
Let us provide a more detailed explanation of the syntax for Pandas GroupBy.
GroupBy Method With Arguments
The basic syntax for the groupby operation is as follows:
# Short Aliases for GroupBy Method
Dfg = df.groupby(
by_cols, # Group by these columns
ax=0, # Group along rows (0) or columns (1)
lvls=None, # Group by specific levels (for multi-level index)
idx=True, # Use grouped labels as the result index
srt=True, # Sort the resulting groups by the group key
keys=True, # Add keys to identify groups when applying functions
df=False, # Return a DataFrame if grouped data is a single key
obs=False, # Only show observed values for categorical data
na=True # Exclude groups with missing values (NaN)
)The result of the groupby operation is a special kind of DataFrame called DataFrameGroupBy (Dfg). Think of it as a container that holds your data grouped by certain criteria. It is a special DataFrame that holds smaller parts of the original DataFrame, each part pointing to a distinct group.
Refer official Pandas site for more info on GroupBy Count.
GroupBy Example
Imagine we have a dataset containing information about different categories (‘A’ and ‘B’) and corresponding values. Our task is to understand the distribution of values within each category and obtain a summary of occurrences for further analysis.
Approach:
We’ll be using the Pandas library in Python to solve the problem. Specifically, we’ll employ the groupby operation, which allows us to group our data based on the ‘Type’ column. This operation enables us to create subsets of the data for each unique category. Additionally, we’ll set the as_index parameter to False to ensure that the grouping column (‘Type’) remains a regular column in the resulting DataFrame.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
dict = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(dict)
# Grouping by 'Type'
group_data = df.groupby('Type', as_index=False)In the above code, we called the Pandas GroupBy() function to group the values based on categories. This will allow us to do a more in-depth analysis of value distributions within each category. The final result is saved to group_data object which will be the starting point for further exploration and insights.
Pandas Count()
The count function in Pandas is used to count the number of non-null values in each group. It is commonly used in conjunction with the groupby operation. Here is the syntax and an example:
Count Method With Arguments
result = grouped['column'].count()grouped: The DataFrameGroupBy object obtained from thegroupbyoperation.['column']: The column or columns for which you want to count non-null values within each group.
Count Example
Consider a dataset containing information about different categories (‘A’ and ‘B’) and corresponding values. We want to understand and quantify the occurrences of each category in our dataset.
Approach:
To address this, we’ll utilize the Pandas GroupBy operation to group the values based on the ‘Type’ column. Subsequently, we’ll employ the count function to calculate the number of occurrences within each category.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
dict = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(dict)
# Grouping by 'Type' and counting occurrences
group_data = df.groupby('Type')
count_per_cat = group_data['Value'].count()The above code demonstrates how to use Pandas to group values by categories and count the occurrences within each category. The result is saved in the count_per_cat. It provides valuable information about how many times each category appears in the dataset, contributing to a better understanding of the distribution of categories.
Now, as we know this combination of Pandas GroupBy and Count helps us solve many problems. So, let’s explore what can we achieve by using them.
Data Exploration Using Pandas GroupBy and Count
Categorical Analysis
When dealing with categorical data, you often want to understand the distribution of categories. Grouping by a categorical column and using count helps you quickly see how many occurrences each category has.
Let’s understand this with the help of an example.
When working with datasets that involve categorical data, it’s often crucial to delve into the distribution of various categories. Our objective is to discern the occurrences of each category within a designated column and obtain a concise overview of their distribution.
Approach:
We’ll use Python’s Pandas library to make things easier. First, we’ll group the info based on a category. Then, we’ll quickly count how many times each category appears in the dataset.
Python Code:
import pandas as pd
# Creating a dummy DataFrame with categorical data
dict = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B']}
df = pd.DataFrame(dict)
# Grouping by 'Type' and counting occurrences
group_data = df.groupby('Type')
count_per_cat = group_data['Type'].count()
# Convert the Series to a DataFrame for better printing
result_df = count_per_cat.reset_index(name='Count')
# Print the result
print("Distribution of categories:")
print(result_df)The result will be as follows:
Distribution of categories:
Type Count
0 A 5
1 B 4This code uses Pandas GroupBy to generate a DataFrame with categorical info and then counts the occurrences of each category. After that, it prints the distribution in a DataFrame in pretty format.
Solving Problems Related to Multivariate Analysis
Grouping by multiple columns allows for a more nuanced analysis, especially when trying to understand the interplay between different factors in your dataset.
Consider the below problem scenario to understand this.
We have to analyze a dataset having multivariate data by grouping it based on multiple columns, enabling a more nuanced exploration of relationships between various factors.
Approach:
To illustrate this, we will utilize the Pandas library and call its GroupBy method on multiple columns. It will allow us to create subsets of the values based on the unique combinations of these columns. This lets us examine how different factors interact within the dataset.
Python Code:
import pandas as pds
# Creating a dummy DataFrame with multivariate info
dict = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'SubCat': ['X', 'Y', 'X', 'Y', 'X', 'Y', 'X', 'Y', 'Y']}
df = pds.DataFrame(dict)
# Grouping by both 'Type' and 'SubCat' and counting occurrences
grp_data = df.groupby(['Type', 'SubCat'])
count = grp_data['SubCat'].count()
# Convert the Series to a DF for better printing
rc = count.reset_index(name='Count')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the result
print("Dist. of combinations:")
print(rc)When you run this code, it prints the output in four columns and three rows.
Dist. of combinations:
Type SubCat Count
0 A X 4
1 A Y 1
2 B Y 4In the above code, we used Pandas to perform multivariate analysis by grouping the info based on multiple columns (‘Type’ and ‘Subcat’). The results count facilitate a detailed exploration of the dataset and insights into the distribution of occurrences for unique combinations of these factors.
For Generating Aggregated Summary
Quick Summary Statistics
Counting occurrences within groups provides a concise summary of your data. It’s a quick way to see which categories are more prevalent or less common.
Let’s try to demonstrate this with a problem and its solution.
When working with data, the aggregated summary stats can provide valuable insights into the overall characteristics of the dataset. Our task here is to aggregate and summarize the info efficiently to provide a concise overview of key statistics.
Approach:
To achieve this, we will need to use Pandas Groupby operation, along with aggregate functions. It will allow us to quickly calculate summary statistics such as the sum, mean, and count of values within each group.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
dict = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(dict)
# Grouping by 'Type' and obtaining quick summary statistics
grp_data = df.groupby('Type')
stats = grp_data['Value'].agg(['sum', 'mean', 'count']).reset_index()
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the result
print("Summary Stats:")
print(stats)The results are as follows:
Summary Stats:
Type sum mean count
0 A 89 17.80 5
1 B 91 22.75 4In summary, our goal is to use Pandas to group the info by the ‘Type’ column and calculate quick summary statistics for the ‘Value’ column within each group. The resulting summary_statistics DataFrame provides a concise overview of the total sum, mean, and count of values for each category, aiding in a rapid understanding of key statistics in the dataset.
How to Measure Total Counts
Using size() instead of count() allows you to obtain total counts, including NaN values, which might be useful in certain situations.
Here is an example where we have to calculate the total count.
In certain data analysis scenarios, it is essential to obtain total counts, including the presence of NaN values, to capture a complete picture of the dataset. We aim to calculate the total count of entries within each group while considering the inclusion of NaN values.
Approach:
To solve this, let’s leverage the Pandas count() function instead of size() within the GroupBy operation. This allows us to obtain the total counts, including NaN values, for each group in the dataset.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
dict = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B']}
df = pds.DataFrame(dict)
# Grouping by 'Type' and obtaining total counts, including NaN values
grp_data = df.groupby('Type')
total = grp_data['Type'].count()
# Convert the Series to a DF for better printing
rc = total.reset_index(name='Total Count')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the result without additional information
print("Total Counts, Including NaN:")
print(rc)The output would display like the following:
Total Counts, Including NaN:
Type Total Count
0 A 5
1 B 4In summary, our objective is to use Pandas to group the info by the ‘Type’ column and obtain total counts for each group, considering the presence of NaN values. The resulting total_counts provides a comprehensive view of the number of entries within each category, including the instances where values might be missing.
How to Use for Data Cleaning
Identifying Missing Data
By grouping data and using count, you can quickly identify missing values or incomplete details within specific groups.
Check this example.
Effective data cleaning involves identifying missing values or incomplete info within specific groups. We want to quickly identify and quantify the missing values within each group based on a categorical column.
Approach:
To handle this, we will take advantage of the Pandas GroupBy operation, combined with the count function, allows us to identify missing details by comparing the total expected count with the actual count of entries within each group.
Python Code:
import pandas as pds
import numpy as np
# Creating a dummy DataFrame with missing info
dict = {'Type': ['A', 'B', 'A', np.nan, 'A', 'B', 'A', 'A', np.nan]}
df = pds.DataFrame(dict)
# Grouping by 'Type' and identifying missing details
group_data = df.groupby('Type')
missing = group_data['Type'].count()
# Convert the Series to a DF
rc = missing.reset_index(name='Missing Values Count')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Pretty print the result without add. info
print("Missing Values Counts within Each Group:")
print(rc)The execution will produce the following result:
Missing Values Counts within Each Group:
Type Missing Values Count
0 A 5
1 B 2This code creates a DataFrame with missing info, groups it by the ‘Type’ column, and counts the occurrences of missing values within each group. The result is then printed in a clear format.
Using for Reporting and Visualization
Building Reports
In the process of creating reports or visualizations, employing the Pandas GroupBy function to collect counts for each group is essential. It plays a crucial role in developing presentations that are both coherent and informative.
Take this example to understand.
Our task is to generate a report that includes aggregated information for each category, providing a clear and concise overview.
Approach:
To accomplish this, we can accommodate the Pandas GroupBy method, combined with appropriate aggregate functions. It will allow us to create a report summarizing key information within each category.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
data = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B']}
df = pds.DataFrame(data)
# Grouping by 'Type' and building a report with counts
grp_data = df.groupby('Type')
counts = grp_data['Type'].count()
# Convert the Series to a DF for better printing
rpt = counts.reset_index(name='Count')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Pretty print the report without add. info
print("Report with Counts within Each Category:")
print(rpt)After execution, we’ll get the following output:
Report with Counts within Each Category:
Type Count
0 A 5
1 B 4In summary, our objective is to use Pandas to group the data by the ‘Type’ column and generate a report containing group-wise counts. The resulting report provides a foundation for building presentations or visualizations that convey the distribution of categories within the dataset.
Using GroupBy for Plotting
The results of a groupby operation can be easily visualized using various plotting functions in Pandas or external libraries like Matplotlib or Seaborn.
Check this example for plotting the groupby results.
Visualizing data is essential for gaining insights and effectively communicating findings. We want to plot the results of a GroupBy operation to visually represent the distribution of categories within our dataset.
Approach:
To achieve this, we will use the Pandas library in Python for grouping and leverage a plotting library like Matplotlib or Seaborn. The GroupBy operation, combined with appropriate plotting functions, will enable us to create visual representations of the data.
Python Code (using Matplotlib):
import pandas as pds
import matplotlib.pyplot as plt
# Creating a dummy DataFrame
data = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B']}
df = pds.DataFrame(data)
# Grouping by 'Type' and plotting the results
group_data = df.groupby('Type')
rpt_counts = group_data['Type'].count()
# Convert the Series to a DataFrame for better plotting
rpt = rpt_counts.reset_index(name='Count')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Plot the results
plot = rpt.plot(kind='bar', x='Type', y='Count', rot=0)
plt.xlabel('Type')
plt.ylabel('Count')
plt.title('Dist. of Categories')
plt.show()Once run, the above code would plot a bar chart as shown below:
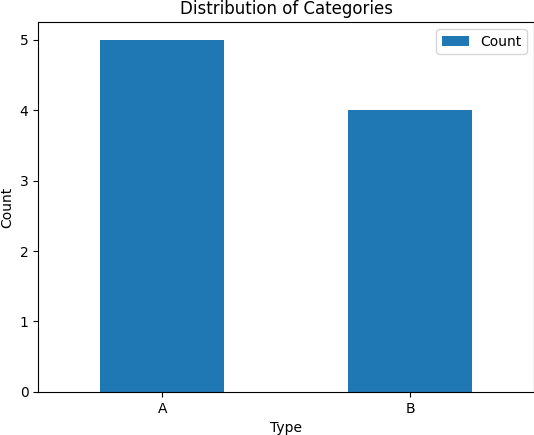
In summary, our goal is to use Pandas for grouping the data by the ‘Type’ column and then employ a plotting library (Matplotlib in this example) to visualize the distribution of categories. The resulting plot provides a clear representation of the count of each category, aiding in the interpretation of the dataset.
Using GroupBy and Count with Condition
Add Conditions in GroupBy
You can use the counts to filter groups based on certain conditions. For example, you might want to filter groups where the count is above a certain threshold.
Let’s practically see how can we use conditions with groupby and count.
In certain scenarios, we may want to filter groups based on specific conditions, allowing us to focus on subsets of the data that meet certain criteria. We aim to perform conditional filtering on grouped data, selecting groups that satisfy predefined conditions.
Approach:
To address this, we will use the Pandas lib. The groupby operation, combined with conditional filtering using a custom condition or function, will enable us to extract groups that meet specific criteria.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
data = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(data)
# Grouping by 'Type' and doing condnl filtering
grp_data = df.groupby('Type')
filter_grps = grp_data.filter(lambda x: x['Value'].count() > 1) # Updated condition for demo
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the filtered groups
print("Filtered Groups:")
print(filter_grps)The output of the above code:
Filtered Groups:
Type Value
0 A 10
1 B 20
2 A 15
3 B 25
4 A 12
5 B 18
6 A 22
7 A 30
8 B 28In summary, our objective is to use Pandas to group the data by the ‘Type’ column and perform conditional filtering on the groups based on a specific condition (mean value of ‘Value’ greater than 15 in this example). The resulting filter_grps contain only those groups that meet the specified condition, allowing for focused analysis on relevant subsets of the data.
Using Pandas GroupBy and Count for Data Preprocessing
Feature Engineering
Grouping and counting can be part of feature engineering when creating new features based on the distribution of data within groups.
Below is a simple data preprocessing example.
In data preprocessing, feature engineering involves creating new features or modifying existing ones to enhance the model’s performance. We want to use the groupby operation to perform feature engineering, creating new features based on the distribution of data within groups.
Approach:
To achieve this, we will use the Pandas library in Python. The groupby operation, combined with feature engineering logic, will allow us to create new features that capture information about the distribution of values within each group.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
data = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(data)
# Grouping by 'Type' and doing feature engineering
grp_data = df.groupby('Type')
df['Mean_Value_per_Category'] = grp_data['Value'].transform('mean')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the updated DF with the new feature
print("Updated DataFrame with Feature Engineering:")
print(df)This code would produce the following result:
Updated DataFrame with Feature Engineering:
Type Value Mean_Value_per_Category
0 A 10 17.80
1 B 20 22.75
2 A 15 17.80
3 B 25 22.75
4 A 12 17.80
5 B 18 22.75
6 A 22 17.80
7 A 30 17.80
8 B 28 22.75In summary, our goal is to use Pandas to group the data by the ‘Type’ column and perform feature engineering by creating a new feature (‘Mean_Value_per_Category’ in this example) that captures the mean value of ‘Value’ within each group. This process enhances the dataset with additional information, potentially improving the performance of machine learning models.
Ensuring Quality of Data
Data Validation
It helps in quickly validating the integrity of your data by ensuring that groups contain the expected number of entries.
Consider this example to understand how to validate data.
Ensuring the integrity and quality of the data is a crucial aspect of data analysis. We want to perform data validation by quickly checking if groups contain the expected number of entries and identifying potential inconsistencies or issues.
Approach:
To address this, we will use the Pandas library in Python. The groupby operation, along with data validation checks using functions like size(), will allow us to validate the integrity of the data within each group.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
data = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(data)
# Grouping by 'Type' and performing data validation
grp_data = df.groupby('Type')
status = grp_data.size().equals(df['Type'].value_counts())
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the status
print("Data Validation Status:", status)The result will give an update on the validation done.
Data Validation Status: TrueIn summary, our objective is to use Pandas to group the data by the ‘Type’ column and perform data validation checks. The result status indicates whether each group contains the expected number of entries, providing a quick validation of the data’s integrity within each category.
Keep Code Clean and Efficient
Compact Syntax:
The pair of Pandas GroupBy and Count provides a concise and readable syntax to perform complex operations in just a few lines of code.
Instead of talking, understand this idea with the below example.
Code efficiency is essential for readability and performance. We aim to achieve compact syntax when performing complex operations using the groupby operation, making the code concise and easy to understand.
Approach:
To address this, we will use the Pandas library in Python and leverage the compact syntax provided by Pandas functions. We’ll aim to perform complex operations using a concise and readable syntax.
Python Code:
import pandas as pds
# Creating a dummy DataFrame
data = {'Type': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A', 'B'],
'Value': [10, 20, 15, 25, 12, 18, 22, 30, 28]}
df = pds.DataFrame(data)
# Compact syntax for grouping and counting
result = df.groupby('Type')['Value'].count().reset_index(name='Count')
# Set the display width for pandas
pds.set_option('display.max_columns', None)
pds.set_option('display.expand_frame_repr', False)
# Print the result
print("Compact Result with Count:")
print(result)When we run this code, it prints the following output:
Compact Result with Count:
Type Count
0 A 5
1 B 4In summary, our goal is to use Pandas to perform complex operations, such as grouping, counting, and calculating the mean, using a compact and readable syntax. The resulting result DataFrame provides a concise summary of the count and mean value for each category, demonstrating the efficiency of the code.
By now, you must have realized that using Pandas GroupBy and Count together is like playing a Swiss knife. It can help you explore, aggregate, and understand data effortlessly, making it simple to derive insights from your dataset. If you have any queries, do shoot us an email and ask.
Python for Data Science
Check this Beginners’s Guide to Learn Pandas Series and DataFrames.
If you want us to continue writing such tutorials, support us by sharing this post on your social media accounts like Facebook / Twitter. This will encourage us and help us reach more people.
Happy Coding,
Team TechBeamers





